

Reproducing The Blue Screen of Death
Reproducing The Blue Screen of Death
Meehl's Philosophical Psychology, Lecture 8, part 3.

This post digs into Lecture 8 of Paul Meehl’s course “Philosophical Psychology.” You can watch the video here. Here’s the full table of contents of my blogging through the class.
I wrote yesterday that we should be pedantic about the distinction between reproducibility and replicability. A result is reproduced when someone applies the same analysis to the same data and finds the same result. A result is replicated when someone reimplements the same study and finds the same result. Reproduction should be mandatory, but replication is far more subtle.
Now, if you really want to get pedantic, reproduction turns out to be more subtle than I made it out to be. Never forget, computer scientists can always be more pedantic than you can. Commenter Chris made a brilliant point that I will try to articulate here for all of you who aren’t computer scientists. And thanks to computer scientists Eric Jonas, Chris Re, Stephen Tu, and Shivaram Venkataraman for helping me flesh out this articulation!
Let’s say that a paper comes with a code repository that uses version 9 of Stata. I open my current copy of Stata 17 and find their scripts don’t run. I dust off the installation compact disk with Stata 9, find my external CD drive, and try to install the old Stata version. But now I find MacOS Sonoma doesn’t support the old binaries. Shoot. Now I get into the crawl space under my house and pull out my iMac G5… Anyway, you see where this absurdity goes. If no one can run the code without finding a computer and software from 2005, is this result reproducible?
Suppose I take their code and port it to Python. I’m able to recreate all of the graphs in the original paper and most of the tables, too. But porting code is a reimplementation, and hence, my analysis isn’t technically the same. Is that a reproduction or a replication?
For complex code pipelines, reproduction can be an issue on much shorter timescales. Chris told me about how Huggingface's model reproduction pipeline maintains Python scripts that build and change models. These scripts are not allowed to be updated. If there are bugs, or if a version of some package is updated, you might lose the model forever.
And when you get really down into the weeds of things, you discover subtlety in what we could even ask for. Computers, which we treat as these cold, precise, infinitely reproducible calculating machines, are a mess of ambiguity. Most people never think about it, but “real number” algebra on computers, the computation we use to simulate reality or calculate statistical integrals, is based on digital processes. These digital approximations produce compounding errors.
We use a convention called “floating point arithmetic” to approximate real numbers with ones and zeros. If not carefully implemented, floating point arithmetic is decidedly hard to reproduce. Because silicon fixes the number of bits you can use to represent a number, you throw away some of your computation at every step. For intuition, take this caricatured example: suppose we can only represent numbers by one digit and a power of 10. Then even though 30 times 80 really equals 2400, the computer can only use the first digit and stores the outcome as 2000. 900 times 70 is stored as 60,000. And so on. Floating point math does a similar sort of truncation, though with many more digits.1 These truncations break some of the basic laws of math that we take for granted. For example, the identity
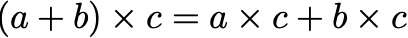
is not exactly true because of floating point truncation (i.e., floating point arithmetic is not associative). Little issues like this mean that a compiler or interpreter might read the same line of code, implement it in two slightly different ways, and yield a slightly different number. Perfect, bit-for-bit reproduction becomes impossible.
Computer scientists have noted that if two people compile the same code, there isn’t an easy way to check whether the artifacts are bit-for-bit the same function. They are, in fact, most likely not identical. Does it matter? The answer is usually no. But sometimes yes! What counts as reproduction then? Where do we draw the line? Yesterday I wanted to argue for pedantry, but now am back arguing for pragmatism.
A simple eye test suffices here. Reproduction is just about communication. It is you showing me what you did. It is a way that I can check your work. Replication, however, is about robustness. It is about how your findings and predictions change due to small changes in the derivation chain. Let’s apply this dichotomy to software. Reproduction demands that you have something at the time you did the work to show that it works. If your code doesn’t explain why you dropped ten thousand of the forty thousand units in your final analysis, then your result is not reproducible. On the other hand, if I change the random seed in your code and am unable to reproduce your figures, your work isn’t replicable. Your general scientific theory is probably very fragile. IYKYK.
In computer science research, we’re in a far better state of reproducibility than ever. Sure, old machine learning models get deprecated, but the models that persist are the ones that are robust to code perturbations. You want a model to be reproducible to get your audience’s attention. You want it to be robust (and replicable) to keep their attention.
While the line between reproduction and replication is sort of grey, it’s just not that grey in the vast majority of cases. You should have code that’s runnable by the reviewers and colleagues. They should be able to reproduce all of the numbers in your paper, which means that the floating point issue shouldn’t propagate to the level of differences in the numbers and plots in the published report. If your code doesn’t run a week from now, then that’s on you. It’s perfectly fine and fair for us to dismiss papers that are fragile. This is pedantic enough for me.
Except in neural nets, where this single-digit floating point is what we do these days.
I don't take my own advice, but my advice is to encapsulate the entire analysis chain in a docker container so that you have the right versions of all libraries, etc. It's obviously not a complete solution, because the container might run differently on different hardware.
This issue reminds of the connection between robustness and generalization in ML https://jmlr.csail.mit.edu/papers/v2/bousquet02a.html . If your trained model performs well on train set and you end up with nearly the same model after introducing perturbations to the train set and retraining, then this model will perform well on test set. To stretch the analogy, perhaps the "trained model" can be viewed as the derived theory and different groups replicating the study give perturbations of the training set